![]() From day one at Rival IQ, we bet on Node.js as our core platform. We found Node, with its JavaScript expressiveness and its simple concurrency model, to be more productive than previous generation platforms; and yet, due to its complex control flow and awkward error handling, way less productive than it could be! This led us to choose Streamline as a key companion tool.
From day one at Rival IQ, we bet on Node.js as our core platform. We found Node, with its JavaScript expressiveness and its simple concurrency model, to be more productive than previous generation platforms; and yet, due to its complex control flow and awkward error handling, way less productive than it could be! This led us to choose Streamline as a key companion tool.
How does Streamline help with Node?
Streamline elegantly addresses these Node weak spots and provides substantial incremental productivity gains. This blog post explains how we made these decisions, and why I encourage you to look at this pair of technologies too if you are building applications.
The top 3 advantages of Node.js
So first, why Node? Node has a number of compelling aspects, including a great package management system, a speedy runtime, and an active and rapidly growing community. However the Node attributes that resonate the most with me concern developer productivity.
Coming from building previous large scale systems in Java and C# (and C++ before that), I saw three huge advantages:
- A simple, scalable concurrency model. The event loop model of Node is a proven approach to simplifying reasoning about concurrency. The places where your code yields are explicit, and your code will not be interrupted elsewhere. This is awesome. Explicit synchronization is infrequently required. By contrast, many platforms achieve concurrency via threads, but then force you to protect shared state against any conceivable race, which is just plain hard to get right (as well as adding synchronization overhead). As I started writing Node code and realized I didn’t have to put critical sections everywhere anymore, it felt like a real burden lifted. Furthermore, the event loop model of Node scales well for most real world app scenarios (i.e., I/O bound).
- Simplicity and expressiveness. JSON is fantastically simple, and it’s the native data format of JavaScript. I love being able to declare objects on the fly, without having to create a new class, probably in a new file, with a bunch of getters/setters and other boilerplate, perhaps some XML configuration too, all just to pass some data around from A to B. I find I can do things with so much less code than the previous generations of languages.
- One language to rule them all. Sure, JavaScript has its warts, but it is great to have one language that spans your product front to back. Why is this important? Because having a highly functioning team of full-stack developers is dramatically easier that way. In a previous life, I ran an engineering team that had Java on the server and Flex (Flash) on the client. Despite a talented team, we had an absolute divide between front-end and back-end; it was pulling teeth to get developers on one side to even look at the code across the chasm, and this hurt our productivity.
When I designed the Active Server Pages platform at Microsoft in the mid-nineties, it was all about letting you use languages like VBScript and JavaScript on the server side, within a concurrency-managed container, in order to make web application development easy (and the data say we succeeded in creating a productive environment with ASP). So Node is like coming home to me… a much more powerful home that is! 😉
There remain some challenges
All told, I like many things about Node; but that said, Node isn’t perfect. Nothing is. Some of the challenges we’ve faced have to do with the relative immaturity of the platform. The tooling, while constantly improving, is still weak in some areas. (If you’ve had to track down a non-heap memory leak for example, you’ll know exactly what I mean.)
There are still breaking changes that happen in common modules relatively frequently. It’s sometimes hard to tell which of the N competing libraries that do nearly every task will take off and which will wither.
Managing control flow is biggest issue
But my main hang-ups have to do directly with developer productivity issues of the platform itself. Despite Node being on the whole much more productive than previous generation environments, out of the box Node is way less productive than it can be. Why? To summarize, it’s the challenges in managing control flow.
Specifically:
- Sequencing asynchronous function calls is clunky (e.g. do A, then B, then C), particularly with more complex business logic (i.e. longer sequences). It’s even worse if there are branches in the flow.
- Looping over sequenced asynchronous function calls is clunky (e.g. do A for each of this set of items, one or N at a time).
- Error handling is, bluntly, a mess. Code you call can throw exceptions. It can return errors via callbacks. It can raise error events. Exceptions can happen with or without your own app code on the call stack. If you didn’t write the module you’re using (and hopefully you are leveraging all those great modules out there in npm!), you need to be extremely defensive. Or carefully read the entire recursive tree of dependencies. Or cross your fingers. And then still there are errors where the best you can do is die and restart. See here for one write-up that explains the intricacies of handling all the various flavors of errors.
- Manually enforcing strict async behavior in your async functions is fragile. For example, a common code pattern is: check if I have a result in memory already and return it if found (sync), if not go fetch it (async). On the sync path, you must explicitly delay invoking the callback until the next turn of the event loop. Fail to do that, and all kinds of things can break, like blowing your stack or breaking assumptions about the order of operations.
- Manually protecting against accidentally calling a given callback more than once is fragile. For example, calling a callback early on an error path, but forgetting to return there or alternatively guard the happy path with an else. Its easy to introduce and can be tricky to track down bugs like this.
Many projects working to overcome these Node issues
I think the vast majority of people who write apps in Node feel this pain. The many projects out there that attempt to address some or all of these issues (via control flow functions, promises, or other approaches) are strong evidence of this. Joyent, the official keepers of the Node flame, recently came out with a set of Node best practices that recommend the use of a control flow library to help tame these concerns.
Great. But which control flow approach to use?
After running into these issues when we first started building Rival IQ in Node, I adopted async. This is a powerful library, and it was a big step forward on addressing sequencing and looping, and helped somewhat on error handling by at least centralizing handling of error results from callbacks.
But after writing quite a bit of code in that model, I just wasn’t happy. The code base was full of boilerplate code, it was hard to maintain and refactor, it had subtle latent bugs that I kept finding, and at the end of the day, it was just not as productive or fun as I wanted. I honestly felt embarrassed to bring more engineers onto the project in that state (which, to be clear, was my fault, not the fault of any library I was using). I longed for the ability to write code in a more natural way, one where I didn’t feel like I was coding standing on my head. I’m not good at standing on my head.
Enter Streamline
Simply put, Streamline is a tool that lets you write Node code using all the control flow primitives of the JavaScript language (sequences of instructions, branches, loops, try/catch/finally, etc.) in a natural way, including for async function calls.
Streamline takes care of yielding for the async work to complete and then resuming the logical flow of control automatically on your behalf. That means that you can write your control flow as if these async functions were synchronous. Of course, under the covers, the Node event loop continues to run; no blocking or busy-waiting occurs.
How does Streamline know to do this? In Streamline, you replace the callback functions you would normally pass into async function invocations with an underscore (“_”). This underscore is a special token recognized by the Streamline parser, which tells Streamline to yield here and wait for results. If the call succeeds, the asynchronous results are presented as the return value of the function. Any error response or exceptions are presented as a thrown exception. In other words, async functions act very much like normal functions. Yeah!
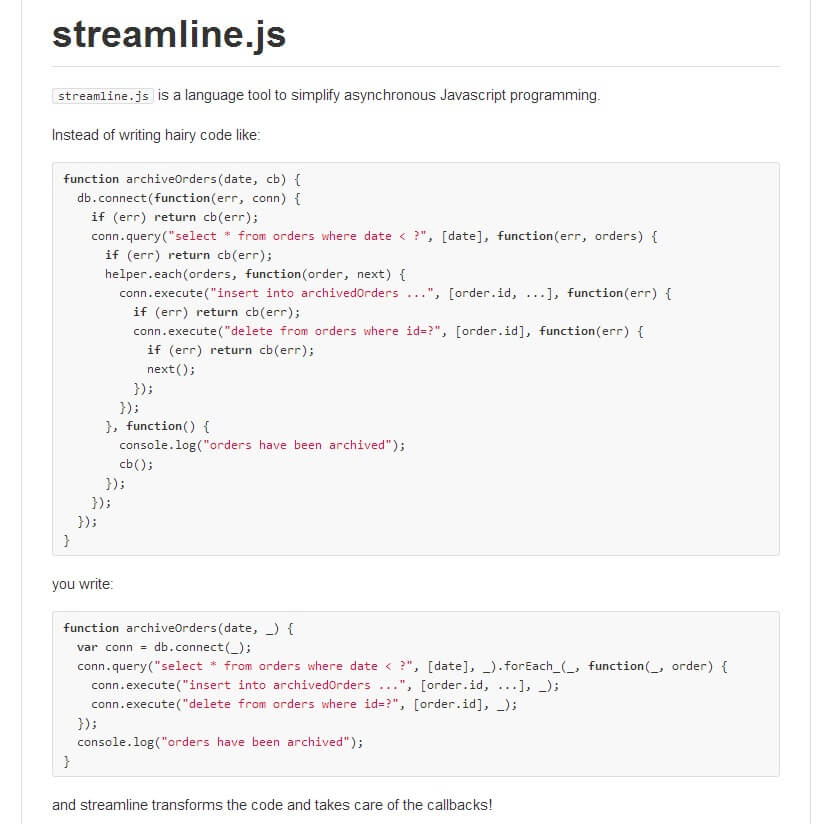
Source: https://github.com/Sage/streamlinejs
Under the covers, Streamline is really its own language, albeit a language that happens to be extremely close to JavaScript. An on-demand compiler automatically converts Streamline source into native JavaScript, with no explicit compile step by the developer. There are several runtime backend options, including translating to auto-generated vanilla callbacks, running on top of a fibers package, or targeting ES6 generators.
Is Streamline the right approach?
There have been vociferous debates in the Node community about whether the Streamline approach and various other competing models are Good things or Bad things. While I appreciate the passion on all sides, it sometimes has devolved from discussion into brawling, which is a shame. We are still early enough in the evolution of the Node platform that there is room for creative approaches and healthy discussion; and no one is making anyone else adopt a particular technology or approach.
Here’s why we use Streamline
Since everyone gets an opinion, here’s mine: if you are building production apps in Node, you’d be foolish not to evaluate Streamline, because of the developer productivity benefits we’ve seen building typical app business logic, i.e. where you need to orchestrate a bunch of I/O tasks like calling APIs, accessing data stores, and the like.
- Simple, expressive control flow. Control flow clunkiness is simply solved. And there is dramatically less pattern noise. (There are code samples below to help illustrate this.) Once you get the hang of Streamline, code is easier to understand, refactor, and maintain. The same concurrency guarantees exist, in that the only places you can be interrupted are well defined – wherever a function is called with the magic underscore token. Furthermore, Streamline practically eliminates whole classes of errors, like accidentally calling a callback twice.
- Error handling is dramatically improved. Returned error objects and thrown exceptions, no matter when they are thrown in the chain of execution (before or after the async work), are all unified via try/catch/finally. (Unhandled event emitters and exceptions thrown with none of your code on the stack still have the same issues.)
- Your existing JavaScript tools work great. Because Streamline syntax is itself valid JavaScript syntax, debuggers, linters, code formatters, syntax highlighting, etc. keep working.
- The debugging experience is actually improved over vanilla Node. Using a tool like WebStorm, you can step through the Streamline source in your debugger (you don’t have to use the compiled artifacts), and when you have a sequence of operations, you can actually just hit next, next, next in the debugger vs. setting a breakpoint on each new nested function context. Awesome. [UPDATE: I’ve posted a screencast demo of this] Furthermore, Error.stack is overridden to show a logical stack trace, as opposed to the often less meaningful ones that you get in vanilla Node where you just see the stack building up from the Node event loop dispatch.
- Streamline plays well with non-Streamline code. Unlike some other control flow approaches, no wrappers are required to call non-Streamline code from Streamline; likewise, non-Streamline code can transparently call Streamline code, and it just sees a standard Node callback shape. (There are a handful of infrequent exceptions, having to do with registering functions written in Streamline with certain non-Streamline code, and with consuming packages that are based only on event emitters and without callbacks, but there are straightforward patterns for handling these cases.) This means it’s very easy to start using Streamline incrementally in part of your project, to test it out.
But be aware…
As always, every technology has its tradeoffs. Two things to be aware of from my experience:
- Performance. Overall, performance of Streamline code is quite good, but there is some cost to the features over going bare metal. See here for some performance tests. In the Streamline fibers mode (which we use), the overhead is pretty low. There is some increased memory usage as well depending on your exact use cases.
- Learning curve. The concepts are straightforward, but as with anything new, there is a ramp up. The main point of confusion is Streamline’s magic underscore token; it isn’t a real function, it’s an instruction to the Streamline parser. That means for example you can’t access it via a closure, you can’t wrap it with another function, etc. It’s also important to understand that the underscore means yield, and when execution hits it, the event loop may run. Also, I’ve seen some cases where folks accidentally name their Streamline source file with a .js file extension instead of ._js, which means it is treated as vanilla JavaScript, and the magic doesn’t work.
Examples of Streamline code
With that background, let me now show you a few examples of Streamline at work, comparing plain Node using callbacks versus Streamline.
The first example is a simple function that logs in a user. It compares the provided email and password with the associated stored hash, and on success updates and returns the user record. This is taken right out of our code, just simplified to remove some bits specific to our environment (by the way, the “db” package is a thin internal database wrapper).
Example 1a: login function, using callbacks
[gist id=8260776 file=example1a.js]Example 1b: login function, using Streamline
[gist id=8260776 file=example1b._js]The vanilla callbacks version in this case is really not too onerous. That said, the Streamline function accomplishes the same task much more succinctly. The biggest win is centralizing error handling. Score one for Streamline. This advantage gets more pronounced as you have more steps or branches in the flow.
The callbacks version also has at least one latent bug. What if any of those called functions throw an exception? We’d like to catch those and map the exception to an error callback response. But to do so, you have to jump through some serious hoops, as mentioned above. Streamline, on the other hand, transparently unifies returned error objects with thrown exceptions.
Next, let’s look at a second example. This one is a bit more complex. Here we grab a set of records, and process through them at some level of parallelism, logging and continuing on any errors. Again, this is abstracted right out of our codebase. I didn’t bother showing this in vanilla callbacks only, as it’s pretty hairy.
Example 2a: analyze function, using callbacks and the async library
[gist id=8260776 file=example2a.js]Example 2b: analyze function, using streamline
[gist id=8260776 file=example2b._js]Here you can see the first version has a lot of pattern noise, while the Streamline version (with the possible exception of the slightly cryptic parameters to the .forEach_ call) is very tight and clear.
Streamline for the win
Streamline is a brilliant piece of engineering that addresses several key weaknesses in Node. We’ve found that moving to Streamline reduced our Node codebase size by roughly a third.
However, its not just concise; we’ve found that it make our code base easier to understand, and has fewer latent bugs. Together, this has significantly increased our productivity in both writing new code and maintaining existing code. Measuring programming productivity is a notoriously squirrely problem. But as a non-scientific estimate, I would say Streamline has given us a 1.5x overall productivity benefit over raw Node. This is HUGE – think about being able to get that much more done.
If you are building applications, I encourage you to give Node plus Streamline a try. We’ve found it to be productive and fun environment. And please let me know how it goes!